 I’ve been beta testing the latest version of SDL Trados Studio since the summer. Four months and nine builds later, Studio 2017 has been officially unveiled and is being rolled out to the thousands of users who pre-ordered the upgrade, have a support agreement in place or are buying Studio for the very first time. What’s in store for them? Fragment recall and repair, an Advanced Display Filter, adaptive machine translation, improved segment merging and more. upLIFT fragment recall and match repair is worthy of a post of its own. So here it is.
I’ve been beta testing the latest version of SDL Trados Studio since the summer. Four months and nine builds later, Studio 2017 has been officially unveiled and is being rolled out to the thousands of users who pre-ordered the upgrade, have a support agreement in place or are buying Studio for the very first time. What’s in store for them? Fragment recall and repair, an Advanced Display Filter, adaptive machine translation, improved segment merging and more. upLIFT fragment recall and match repair is worthy of a post of its own. So here it is.
Fragment recall: Whole TU (translation unit) match
The new upLIFT technology implemented in Studio 2017 means that a whole short segment contained in a longer one is offered through AutoSuggest. I love this because it’s almost infallible. Look at this example, where I’ve translated “capillary electrophoresis” for the first time in segment 341, and three segments later it’s offered as I type:
(Click any screenshot to open it in a separate window)

TU fragment match
Not only whole TU matches are identified, but fragments too:
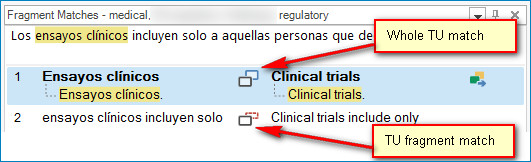
In practice, this new feature more or less replaces AutoSuggest dictionaries, a static resource that has been available since 2009. Fragment Recall offers suggestions in a similar way, on the fly through Autosuggest, but it leverages TMs immediately, without having to build a dictionary. There’s no size restriction either and you get immediate context, because source and target terms are highlighted.
How to enable Fragment Recall:
Most of these options are enabled by default. But I’ll go through them one by one, in case you want to check.
Go to File>Options>Editor>Fragment Matches Window and activate the “Display results…” box:

If you don’t like the default khaki highlighting, this is also the place to choose your preferred colours:

Now, go to File>Options>AutoSuggest and activate “Fragment Matches”:
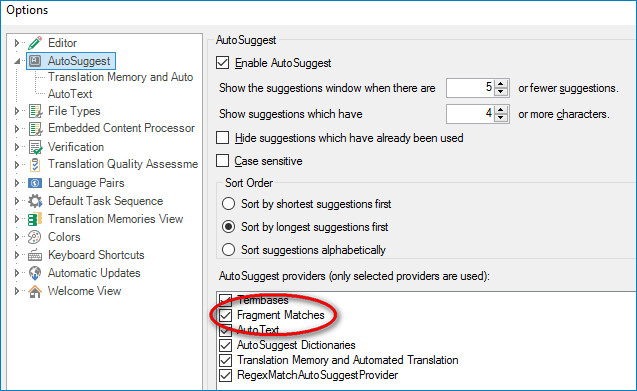
Lastly, to implement fragment matching – which is off by default – and decide on the minimum number of words (and significant words) you want returned in the fragment match window, go to File>Options> Language Pairs>All Language Pairs>TM and Automated Translation>Search and enable TU fragment.

With the above settings, fragment matches will be triggered whenever there are no results in the Translation Results window.
Experiment with the minimum word numbers. You’ll find that a very low number produces too much noise and higher numbers produce fewer results.
Impact on analysis
You may want to consider the impact of fragment matching on a file analysis. The minimum word settings are displayed in an analysis, as is the fragment word count (broken down by whole TU and TU fragment). Unfortunately, there’s no option to exclude this leverage, so watch out for ingenious fuzzy rate grids from penny-pinching agencies.
Layout
By default, the Fragment Matches window is layered under the Translation Results and Concordance windows. You may want to move it to get more vertical space for fragment results. More on this in a coming blog post.
Fuzzy Match Repair
upLIFT technology also comes into play in the new fuzzy match repair feature. Segments are repaired using a variety of resources, such as termbases, aligned translation models (see below), current TMs (whole segments and fragment recalls and even punctuation) and MT (machine translation providers).
![]() When a fuzzy match is repaired, the match percentage remains unchanged and a spanner symbol is added. Therefore, the percentage doesn’t reflect repair work or estimated post-editing, but simply the original fuzzy value.
When a fuzzy match is repaired, the match percentage remains unchanged and a spanner symbol is added. Therefore, the percentage doesn’t reflect repair work or estimated post-editing, but simply the original fuzzy value.
Some repairs need no further editing, some need light editing and others aren’t any good at all, so I just transfer the useful repairs to my translation:

The disadvantage? You can’t transfer unrepaired segments to the Editor window. Check out the last example in the screenshot above. It was perfect before the repair. What we’re missing is a shortcut to transfer a segment in an unrepaired state from the Translation Results window. I’ve added this missing feature as an idea on the SDL community forum. Please vote for it and let’s see if it’s added in a service pack.*
* This feature was added in SR1 (released July 2017).
How to enable Fuzzy Repair:
Go to File>Options>Language Pairs>All Language Pairs>Match Repair and activate “On”. If you want to use machine translation for match repair, enable it here too:

Upgrade TMs
To make use of fragment recall and repair technology, you need to upgrade all your TMs. Whole TU unit recall is the only feature that will work without upgrading your TMs.
The upgrading process involves two steps:
- A translation model is built by performing a statistical comparison of source and target words in each segment. To make this viable, the TM must have at least 1,000 segments. SDL recommends 5,000.
- Segment fragments are identified and aligned. This step takes a long time. For example, one of my TMs with 100,000 segments took about 1.5 hours to upgrade.
Your TM will increase by up to 3 times in size because of the new fragment-aligned content. (Thanks to Helke Heino for pointing this out in the comments below.)
The good news is that the upgrade process is quite simple. Go to the Translation Memories view. Select a TM and click Settings>Fragment Alignment.
When you switch on Fragment Alignment Status, you’re warned that fragment alignment will take a long time, and then the process starts immediately, with the two steps rolled into one.

Automatic alignment after upgrading
After upgrading your TM, make sure future new segments are aligned automatically as you translate. In the same settings window, click Align new content automatically.

By enabling this box, you won’t need to repeat the alignment process ever again.
If you go back and use your upgraded TM in Studio 2015 or earlier, the TM will work correctly, but new content won’t be automatically aligned in earlier versions. In that case, align the new content manually in Studio 2017: Tick the Quick Align box (see above) and then Align Translation Units. That will align new content only and ignore previously aligned segments.
The verdict
The upgrading TM process is a nuisance* and you’ll need to allot a quiet time of day or a weekend to prepare your TMs for the new upLIFT technology. But once it’s done, you’ll find fragment recall and repair is a very useful addition to your toolkit.
In a follow-up post I’ll be looking at some more new features in Studio 2017. Stay tuned!
* Stop press! Batch upgrade your TMs!
The “Reindex TMs” app on the SDL App Store has just been updated to batch upgrade a group of TMs in one go, preparing TMs for the new upLIFT technology. I haven’t tested it myself, but it sounds like a great solution. For more details and a video on this app, see Paul Filkin’s post, “More power to the elbow… upLIFT.”
Translators talk Trados
If you found this blog post useful, you might want to check out the SDL series called Translators talk Trados, where other translators look at different features and explain how they use Studio in their workflow. A great chance to learn more about Studio from colleagues!


This was already featured by MemoQ some time ago. Other MemoQ feature is assembly pre-translating from Termbase, and other translation units. Does Trados include any assembly pre-translating function?
Indeed, Studio is finally catching up with memoQ match patch and fragment assembly! And compared with Deja Vu, deep mining has been around for much, much longer.
Studio 2017 can automatically transfer repaired segments to the current segment in the editor, although I prefer to decide myself which segments are useful and which aren’t. As far as I know, repaired segments aren’t available when pre-translating an entire file. I’ve tried that in memoQ and find the noise quite overwhelming! But, yes, it would be nice to have as an option.
Hi Gabriel and Emma – the pretranslation option will come soon. Stay tuned!
could you precise “soon” (one month, one year)?
Sorry for the late reply – will come in the first half of 2017 – hopefully still in the first quarter in a cumulative update.
Hello Emma,
Thanks a lot for these insights and instructions – saved me a lot ot time!
Just for the records: I upgraded a TM (EN-DE) with 210.000 segments and it took “only” 20 minutes. Seems that this process depends on language pair or lenght of segments or other parameters. What I also noticed: The size of the TM went up considerably from 255 MB to 757 MB!
Thanks for this, Helke. Yes, I forgot to mention that TMs grow exponentially when they’re upgraded because of the new fragment alignment content. I’ll add this to my post.
Your TM upgraded quite fast. I have a powerful machine and an SSD, but I think the upgrading process has improved since I did it a while back in a beta version. Good to hear it’s faster now!
Luckily, I have a big and fast SSD as well. I just heard from Ulrike Walter-Lipow who is at the SDL Roadshow in Berlin today that SDL recommends to use an SSD if you want to use the fragment recall, otherwise it can get very slow. I just worked on a file with the now 750 MB TM and it was as quick as usual.
I have quite a few large TMs, which will become at least 700 MB each after uplifting. Since I use at least 5-6 at a time, I am worried that the translation process will be significantly slowed down. Can you recommend a “big and fast” SSD? 🙂
Emma, great post, thank you!
Zsuzsánna, I am sorry but the SSD in my desktop computer is two years old already, so that won’t be a helpful information for you. I’d describe our usual usage of the SSD with Studio (i.e. quick access to search and read lots of small pieces of information and frequent writing of new small bits and pieces to the drive) to a knowledgeable sales person so that they can make a recommendation.
Dear Zsuzsánna,
you can find good comparative reviews in the Internet.
Have a look as SSD are improving every day
regards
Thank you, Emma. This is so helpful. I am going to try to implement these tools as your blog comes out, to stay on top of everything!
Thanks for this info, it’s really useful!
Pingback: More power to the elbow… upLIFT | multifarious
Thanks for this helpful review, Emma! Since the beginning of the year I have been working with Dragon, dictating all my translations into Studio. That means that ever since I have had no use anymore for the AutoSuggest feature, which I used to love in pre-DNS days. Now I am wondering if it is worth upgrading to Studio 2017 if one does not use the upLIFT feature. I am working with Studio 2015. I would appreciate your insight on that. Thanks! Marita
Good question, Marita.
First, I personally like to keep all my software up to date. I run the latest versions of Studio, MS Office, Abbyy and TO3000 – these are the tools I use every day in my work – and upgrading when new versions come out is only a minimal expense considering the return I get on them (without even considering the extra cost involved when you upgrade from old versions).
Second, there’s far more to Studio 2017 than the new upLIFT feature, as I’m sure you know. I usually have quite small files to process but just by chance this week I’m working on a 70-page document with 36000 segments. The new Advanced Display Filter has been incredibly useful: I translated, locked and hid the number-only segments; then I viewed and translated table contents only; then I translated first repetitions and locked all autoprogated segments; now I’m going through the whole file with ctrl+enter, keeping an eye on all other 100% matches but jumping over the autopropagated segments. It’s made a big, complex project much, much easier.
Thank you so much for sharing your experience! You are, of course, right! Upgrading is always a good idea!
Hi Emma, I’ve just upgraded to Studio 2017 and wanted to upgrade my TMs to use the new UPLift technology, but despite the fact that I’ve migrated the two projects I’m currently working on using the migration tool, no TMs are showing in the TM view so I can’t see how to update them using the Reindex TM app or any other way for that matter. I’ve checked the project settings and they each have about 5 or 6 big TM added, but they aren’t showing in the window. I’m probably missing something really obvious. If not, is there any other way or reindexing and preparing them? Many thanks!
Hi Claire,
The TM view is completely unrelated to your projects.
Just go to the TM view (which should be empty), click Open>Open TM. Browse to your TM and open it.
Now you can follow the steps in the article from “The good news is…” onwards.
Hope that helps!
Emma
Thanks, Emma! In the meantime I’ve downloaded Reindex TM and realised I can add my TM folders from there so something seems to be happening. I suspect this might take some time…. 🙂 Thanks for your help as always!
You’re welcome, Claire! Glad you found another solution in the meantime.
Hello Claire, this was very useful and interesting and I’m definitely going to read your other posts about Studio 2017.
I am particularly interested in the impact of fragment matching on a file analysis. Is the analysis grid in Studio 2017 different from the previous versions? Has a new line for fragment matches been inserted and if yes, could this influence the way agencies do their word counts?
Thank you so much for your insights
Eleonora
I think you mean, Emma, not me, Eleonora! I’m very much a novice at Studio 2017!
Yes, the analysis report has two extra columns reflecting fragment matches (see the paragraph above called “Impact on analysis”. I agree that it could influence agencies’ word counts and it would be much better to make this “feature” optional, in my opinion.
OMG, sorry, both of you 🙂 I’d been reading your exchange before commenting myself and must have got them mixed up
Thank you so much for the additional details, Emma!
I seem to have a recurring problem: when I enable Fragment Matches (which for the moment is a huge disappointment – I have a huge EU TM, and even the best matches are no better than AutoSuggest or Term Recognition), the term recognition somehow glitches. The terms are recognised, but when I start typing, they sometimes appear (so I can insert them with an Enter), sometimes not. More often not. I tried disabling Fragment Matches, but nothing changes: I still keep getting fragment matches (even if I disable everything), and term recognition still doesn’t work properly. I re-indexed and uplifted the TMs, re-organised the termbases, basically re-created the project from scratch, still nothing. I want to turn off Fragment matches completely, at least for a while, because at least the term recognition saves me all the typing I have to do now because of this. What am I doing wrong here?
(Also, the Apply Translation shortcut key doesn’t work with matches from Automated Translation, but after reading up on it a bit more, it seems to me that shortcut keys are a problem overall.)
SSD problem solved, by the way. 🙂
Sorry to hear of your problems, Zsuzsánna. I guess you’ve checked that TB suggestions are at the top of the AutoSuggest list? Have you increased the minimum number of words for a fragment match, so that TB is more likely to appear in AS? Have you tried Ctrl+1 instead of Ctrl+T to apply translation results? Do you use Ctrl+shift+L to call up termbase suggestions only?
If tweaking these and other settings doesn’t work, then I suggest you ask on the SDL forum https://community.sdl.com/ or, if you have a support agreement, submit a support request.
Dear Emma, thank you for your reply and for the suggestions.
TB on top: yes. I checked again, it is on top.
Minimum number of words: changed, still nothing.
Ctrl+1 (and other numbers): not working.
Ctrl+Shift+L: I started using that, since I have no other choice for the moment. 🙂
The way the terms appear is pretty erratic: sometimes they appear when I start typing them, sometimes not, even in the same segment. Sometimes the short ones appear, other times the long ones. So I’ll ask for support from SDL as well. But thank you anyway!
The solution to Ctrl+1 etc not working is often solved by deleting the 3 xml files mentioned in this SDL forum thread.