
A new version of AntConc was released at the end of last year. I spotted the announcement on Twitter and was quick to download and start testing the tool, taking advantage of some downtime over the holidays. Read on for a report on my initial findings, some delightful discoveries and the odd little niggle.
AntConc – a freeware corpus analysis toolkit developed by Laurence Anthony[i] – first appeared 20 years ago. I’ve been using the software for some 10 years now to look for answers to queries that crop up as I translate, doubts related to general language usage and uncertainties in specialised terminology related to, for example, diabetes or cardiology. This post reviews my experience to date with the new version and the main differences I’ve found between AntConc versions 3 and 4.*
[click image to enlarge]
Major new features
Corpus builder
AntConc v.4 comes with a corpus builder, which means you can add raw files to create your own corpora, save them and then quickly pick the one you want to load for a particular query or project. Added bonus: compatible file types now include .pdf and .docx, so you no longer have to use AntFileConverter to convert .pdf files to .txt before processing them. Note that if you try to load improperly encoded files into the new version, you will see a warning and those files will be ignored. Try resaving those files as UTF-8 in a text editor to solve the problem as this is the default that AntConc uses.
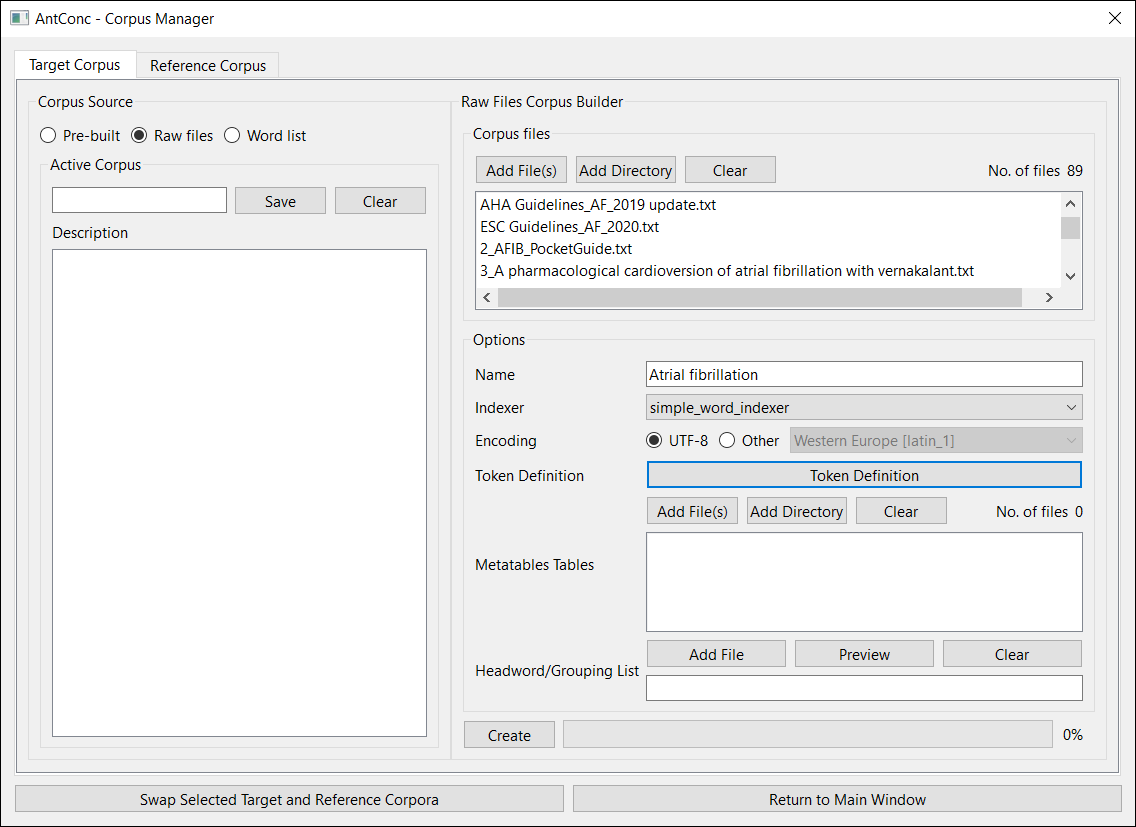
When creating a new corpus, AntConc will identify and tag all the tokens (words). By default a token consists of upper and lowercase letters only but you can tweak the definition to add other characters. I’ve included apostrophes and hyphens to improve word recognition. The Token Testing Area sandbox lets you enter words or sentences to check the outcome before applying the changes:
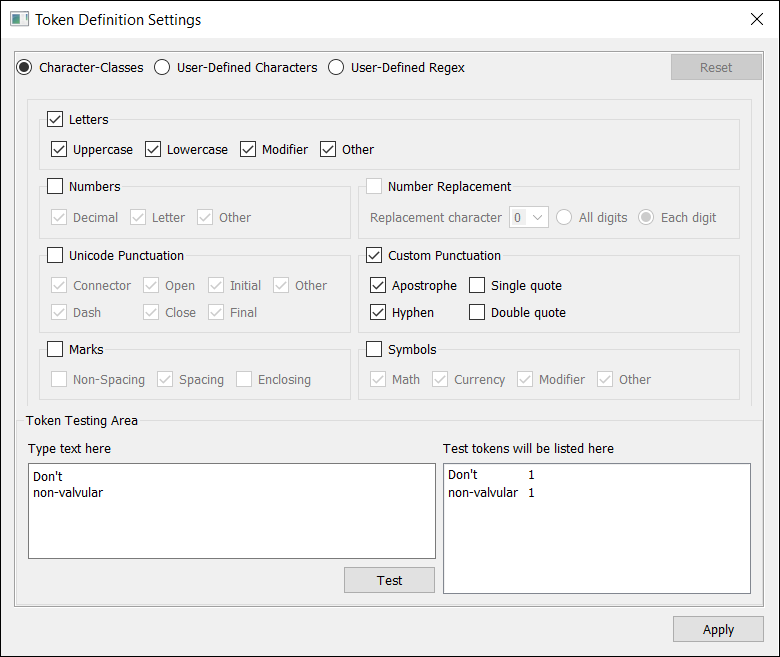
Version 4 still offers the legacy method to create a corpus by simply opening files in the tool. Unfortunately, once you’ve created a Quick Corpus, you can neither add files on the fly nor remove existing ones. I find this more inflexible than before. One workaround is to add new files to a dedicated folder and rebuild the corpus, although large pdfs are slow to process each time, because AntFileConverter works under the hood to convert pdf files to text.
Pre-built corpora – straight out of the box
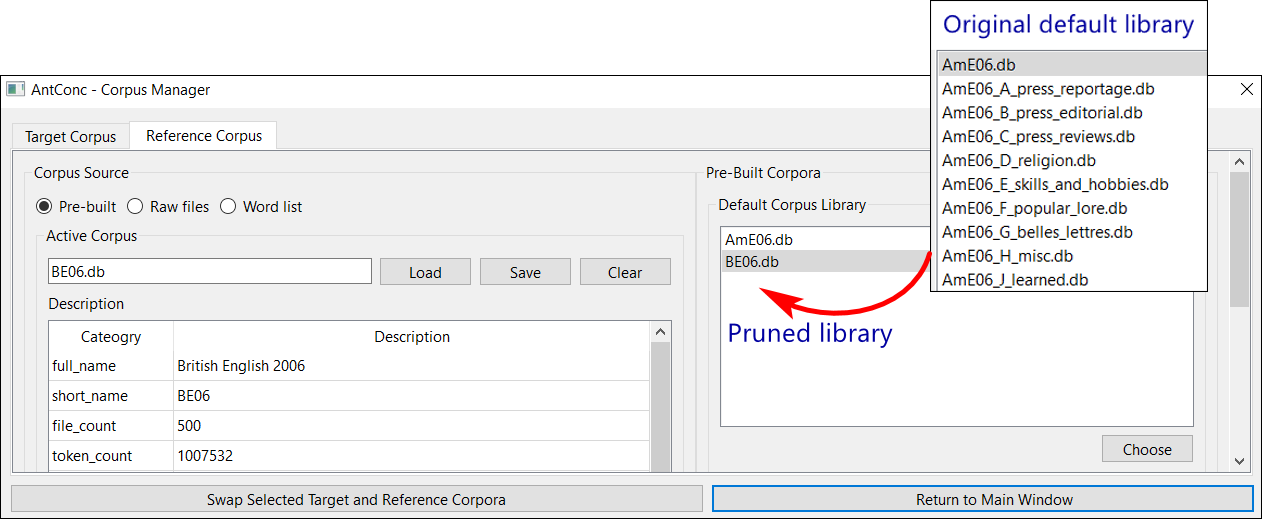
Before, the main window had to be populated with files every time at start-up. Now, you can quickly select a corpus or sub-corpus with the shortcut Ctrl+O (File tab > Open Corpus Manager). AntConc v.4 comes bundled with two large general written corpora, AmE06[ii] and BE06[iii], each containing 500 files and a total of one million words in American or British English, respectively, compiled in 2006. Apart from using them to perform general language queries as a target corpus, you can add them as a reference corpus when investigating word frequency and usage in specialised, custom-built corpora. The default library [AntConc>Corpora>default] was brimming with field-specific subcorpora that I’m unlikely to use, so I moved them out to navigate the library more easily:
[click image to enlarge]
[Edited April 2022] Stop-word functionality was missing in early builds of v.4 but reappeared in v.4.0.6 under Global Settings>Tool Filters. Word lists can now be uploaded to either use or hide a chosen set of words.
KWIC hits by frequency
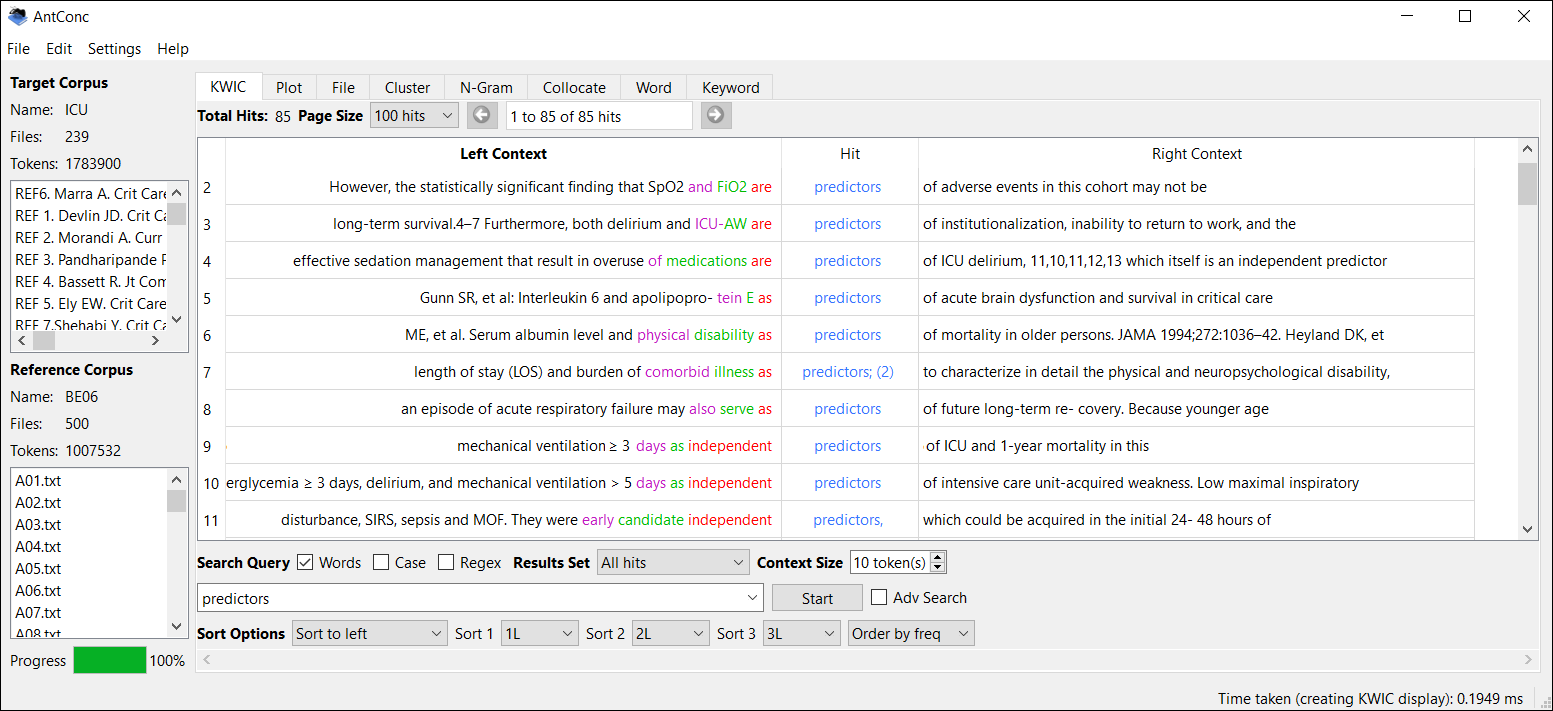
Concordance results in the KWIC tool are now displayed by frequency, informing common word patterns at a glance. Hits can still be sorted alphabetically, but with the fabulous frequency sorting, it’s hard to imagine why anyone would want to switch back to the legacy order.
Under-the-hood access
Corpora are compiled as databases that can be browsed and edited in SQLite-compatible tools. I’ve tinkered in DB Browser for SQLite to compile word lists and edit corpus names. Tip: make a copy of your corpus before you dive in!

[click image to enlarge]
Minor discoveries
- Left pane. Details about the loaded target and reference corpora, including number of files, number of tokens and corpus name, are just a glance away.
- Not in context searches. The KWIC advanced search function not only finds specific words appearing near the search query string but now excludes specific words when the Not in context box is marked.
- N-gram open slots. When searching for n-grams with three or more tokens, you can define an open slot, similar to a joker or wildcard.
- Clone functionality. The clone button has disappeared in v.4. However, you can still run several instances of AntConc simultaneously, making cloning largely redundant.
- Concordance row copying. Before, selecting an entire row to copy elsewhere was unintuitive; now, simply click and drag your mouse across the row to copy and paste it into Word, retaining the AntConc sort colours:

Installation
Previous AntConc versions ran without installation: you opened them simply by double-clicking the .exe file. Version 4, however, installs by default to the Program Files folder, creating a set of subfolders for corpora and the tool itself. I’ve decided to run AntConc from a shared Dropbox folder, to access the tool from my desktop and laptop. Another option is to download a portable version to a USB stick and set up the whole program in a single folder on that device.
Like earlier versions, AntConc v.4 runs on Windows, Mac and Linux systems.
Interface
The new main AntConc window is crisp and clear – unlike these grainy screenshots – with a choice of modern typefaces and font sizes. In the file dialog box (Windows 10 style), you can quickly paste in a path instead of expanding a drop-down tree, branch by branch. In the corpus builder, simply drag and drop files into place.
New, concise tool names in the tabs speak for themselves. The concordance label has been shortened to KWIC (keyword in context), while the cluster and n-gram tools now sit in separate tabs:
Unfortunately, the results pane in the KWIC tool displays source file names in the first column, which means that long names tend to gobble up screen space. (Before, file names could be scrolled out of sight to the right.) However, the shortcut Ctrl+H hides the file name column, kicking into action the next time a search is launched. And for more screen space, you can now completely collapse the left pane containing the target corpus details by dragging the double-headed arrow leftwards.
Still in the KWIC tool, left/right sorting is simpler and more intuitive. The rather confusing legacy tick boxes are gone, replaced by sort options that automatically switch the search to the corresponding side, with dropdowns for selecting sort depth. In fact, all the search query options are more logically labelled and easier to understand than before:
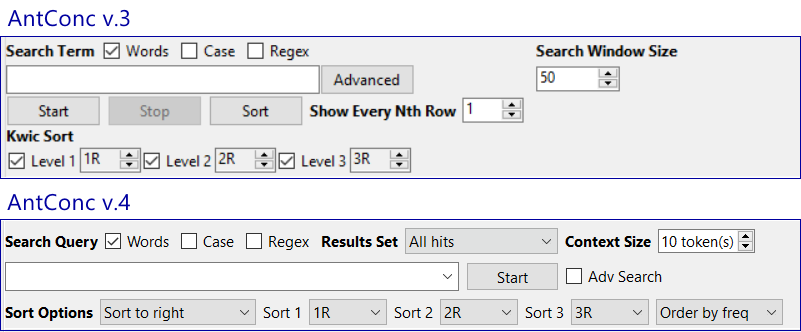
Search query history can be accessed by pressing F4 or clicking the down arrow at the end of the search box. No need to use the keyboard up and down arrows anymore.
Note the Order by freq button in the above screenshot, a major new feature mentioned earlier in this post.
Performance
In v.4, search results flash up on screen almost as soon as you press Start. Even advanced searches with a second search term in context return hits at lightning speed. The engine runs queries in large corpora much faster than before, benefitting from the new SQLite database processing.
Collocate lists appear in seconds. Word list building to calculate collocation significance now happens under the hood.
All in all, AntConc v.4 brings some exciting new features for text workers researching language usage. Whether you want to tease out how words are used in your native language, pick up on nuances in other languages, or solve translation doubts with real-world language examples – AntConc is here to help!
_____________________
* v.3.5.8 and v.4.0.5
[i] Anthony, L. (2022). AntConc (Version 4.0.5) [Computer Software]. Tokyo, Japan: Waseda University. Available from https://www.laurenceanthony.net/software
[ii] Potts, A., & Baker, P. (2012). Does semantic tagging identify cultural change in British and American English? International Journal of Corpus Linguistics, 17(3), 295-324
[iii] Baker, P. (2009). The BE06 Corpus of British English and recent language change. International Journal of Corpus Linguistics, 14(3), 312-337


Gracias Emma por compartir. Yo también soy una usuaria agradecida de AntConc. Es una de mis herramientas favoritas.
Thank you for the nice review. It seems that it is working well! Just one comment: You write that the default encoding has changed, but it hasn’t. The default is still UTF-8 as before. The difference now is that AntConc will flag when the encoding of your files doesn’t match the setting in AntConc.
Thank you for the clarification, Laurence. I’ve edited the post to correct my mistake. And thank you for this new version. I love it!
AntConc 4.0.6 onwards now includes a stop-word feature that is more powerful than in the AntConc 3x series.
That’s great news, Laurence! Thank you for bringing back and improving the stop-word list. I’ll edit the post to mention this change.
Pingback: Localization Reads & Upcoming Events #54